-
 Sabrina Granger authoredSabrina Granger authored
Sabrina Granger authoredSabrina Granger authored
- FAQ pages
- Instructions (not to copy)
- Structure of answer with short answer
- Inserting an image with caption
- FAQ Software Heritage (website)
- 1. General
- 1.1 What is Software Heritage (SWH)?
- 1.2 What is the SWH archive?
- 1.3 What is the size of the archive?
- 1.4 What are the services provided by SWH?
- 2. Archiving software
- 2.1 Which software platforms (forges, package managers, etc.) are archived?
- 2.2 If my code is on GitHub/GitLab/Bitbucket, is it already archived in SWH?
- 2.3 If I delete the repository that contains my code, will the data stay in SWH?
- 2.4 What is the policy for determining what deserves to be archived? are there requirements for a GitHub, Gitlab or XXX repository to be archived by SWH?
- 2.5 Is the code checked for LICENSE file or any specific characteristic in the repository before archiving?
- 2.6 Do you also archive software executables (aka binaries)?
- 2.7 I can't find all my "releases" in a git repository in Software Heritage, what should I do?
- 3. Referencing and identification
- 3.1 What is a SWHID (Software Heritage Identifier)?
- 3.2 What can be identified with a SWHID?
- 3.3 How can I get a SWHID for my software?
- 3.4 Which type of SWHID should I use in my article/documentation?
- 3.5 I want the full SWHID for a source code that is not already in the archive. How can I proceed? How long will it take?
- 4. Access and Reuse
- 4.1 Can I reuse the source code artifacts I find on SWH?
- 4.2 Can I clone a repository using SWH?
- 4.3 Can I retrieve a source code artifact through the API?
- 5. Software metadata
- 5.1 Can I add metadata to my software?
- 5.2 What metadata are preserved from a code repository, with save code now?
- 5.3 What metadata are preserved with a deposited software artifact?
- 5.4 What is the codemeta.json file, why should I use it?
- 5.5 Does Software Heritage perform a check on the metadata (e.g. to verify whether a licence is declared)?
- 6. Research Software
- 6.1 My code is archived in Zenodo, should I also archive the source code in Software Heritage?
- 6.2 My data are in a GitHub repository. Can I archive them with SWH?
- 6.3 Why don’t you provide DOIs?
- 6.4 What are the best practices to use SWH?
- 7. Crediting and software citation
- 7.1 Why should I cite software? and why should I use Software Heritage to do so?
- 7.2 Who should I cite if I retrieve some code from SWH?
- 7.3 I’d like to cite my code archived in SWH. How do I do that?
- 7.4 Should I cite SWH or the author of the code?
- 8. Legal and financial
- 8.1 Should I put a license on my code before saving it in SWH?
- 8.2 Who owns my data in SWH?
- 8.3 How is the metadata licensed? What are policies about accessing metadata? is it different than accessing content?
- 8.4 How can I remove my code from SWH?
- 8.5 How much should I pay to archive my data in SWH?
- 8.6 Does SWH guaranty any timestamping of code archived in case of legal issue?
- 9. Next steps and long term strategy
- 9.1 Where can I find the SWH roadmap?
- 9.2 is SWH sustainable?
- 9.3 What is a SWH mirror?
- 9.4 How can my organization mirror SWH?
- 9.5 What is the time guarantee for the SWH archive?
- 9.6 How does SWH integrate with other preservation strategies?
- 10. Get involved
- 10.1 How do I get in touch with the team?
- 10.2 Can I get an internship? How? Can I get an open position at SWH?
- 10.3 How can I become an ambassador?
- 10.4 How can I become a sponsor?
- 10.4.1 Are there ressources to advocate SWH to my organization?
- FAQ Software Heritage (docs)
- Users
- How can I search the SWH archive? is it possible to search over metadata?
- How are
- Is it possible to do a save request with a link to a .zip or tarball on a website? what file formats are supported with the save code now?
- I tried archiving a repository with the "Save code now" feature. The request seems to be stuck in pending status. what should I do?
- How can I use the SWH dataset?
- Contributors (devel) DONE (we'll open a diff soon)
- Do I need to sign a form to contribute code?
- Will my name be added to a CONTRIBUTORS file?
- What are the Skills required to be a code contributor?
- What are the must read docs before I start contributing? (System architecture, python module dependency etc)
- Where can I see the getting started guide for developers?
- I have SWH stack running in my local. How do I get some initial data to play around?
- Is there a way to connect to SWH archived (production) database from my local machine?
- I have a SWH stack running in local, How do I setup a lister/loader job?
- I found a bug/improvement in the system, where should I report it?
- How do I find an easy ticket to get started?
- I am skilled in one specific technology, can I find tickets requiring that skill?
- Where should I ask for technical help?
- I found a straightforward typo fix, should my fix go through the entire code review process?
- How can I create a user in my local instance? (web application/Django user)
- Should I run/test the web app in any particular browser?
- What tests I should run before committing the code? (It could be specific to the project)
- I am getting errors while trying to commit. What is going wrong? (Must be pre-commit hooks failing...)
- Is there a format/guideline for writing commit messages?
- How do I generate API usage credentials?
- Is there a page where I can see all the API endpoints?
- What are the usage limits for SWH APIs?
- Contributors (Sys-admin)
- SWH releases
- Q: How does SWH release?
- Q: Is there a release cycle?
- Q: git branching strategy?
- Garbage collector
- PHP history
- Docs todos
- DOIs
- New questions to review
- 2022-11-24 Sed Lyon
- Q1 : please, where may i find information on how to take into account the environmental aspects of SWH data storage? How SWH deals with environmental issues?
- Q2: what's the actual size of the archive and which image could be chosen to make the topic less abstract for non-technical audiences ?
- Q3 : where the code is stored ? (different from Q1 that focuses on the impact in terms of resources consumption)
- 2023-04-05 Q&A following Roberto's talk in Lyon
- Q1: What happens if AWS closes?
- Q2: How do you deal with legal aspects? What if a repo contains information that can't be shared?
- Q3: How do you plan the needs in terms of storage?
- Q4: Is there an agreement signed between SWH and the owner of the platform that is harvested? What is the legal framework that allows the regular crawling?
- Q5: The source code in itself isn't always enough. How does SWH provide contextual information about a project?
- Q6: How does SWH deal with the archiving of issues?
- Following HAL training sessions
- Q1: On HAL, it's easy to link 2 versions of a software. What about SWH? Where can I see the articulation between these different versions on SWH interface?
- Following the MediaNormandie webinar
- Q1: Why did you choose to interface SWH with HAL rather than another platform (such as RechercheDataGouv)?
- Q2 : What's the SWH budget model ?
- Retrieved from the general chat room
- If I submit a git repo that isn't on one of the known forges, will SWH periodically refresh it? or only fetch it once?
- Following the DataCite webinar (2023-05-24)
- Q1: What are the biggest shortcomings (features) that publishing platforms have?
- Q2: Are speakers participants aware of plans to implement desirable practices in open publishing platforms, such as OJS or ResearchEquals ?
- Following 2023-06-08 Cirad talk given by Pierre Poulain
- Retrieved from emails with the authors of the Mooc "Reproducible research": use case
tags: documentation, ambassadorsFAQ pages
Ambassador information is now here
Instructions (not to copy)
Structure of answer with short answer
use this template for dropdown
Here is the hidden content
Inserting an image with caption
SWH logo
- FAQ pages
-
FAQ Software Heritage (website)
- 1. General
-
2. Archiving software
- 2.1 Which software platforms (forges, package managers, etc.) are archived?
- 2.2 If my code is on GitHub/GitLab/Bitbucket, is it already archived in SWH?
- 2.3 If I delete the repository that contains my code, will the data stay in SWH?
- 2.4 What is the policy for determining what deserves to be archived? are there requirements for a GitHub, Gitlab or XXX repository to be archived by SWH?
- 2.5 Is the code checked for LICENSE file or any specific characteristic in the repository before archiving?
- 2.6 Do you also archive software executables (aka binaries)?
- 2.7 I can't find all my "releases" in a git repository in Software Heritage, what should I do?
-
3. Referencing and identification
- 3.1 What is a SWHID (Software Heritage Identifier)?
- 3.2 What can be identified with a SWHID?
- 3.3 How can I get a SWHID for my software?
- 3.4 Which type of SWHID should I use in my article/documentation?
- 3.5 I want the full SWHID for a source code that is not already in the archive. How can I proceed? How long will it take?
- 4. Access and Reuse
-
5. Software metadata
- 5.1 Can I add metadata to my software?
- 5.2 What metadata are preserved from a code repository, with save code now?
- 5.3 What metadata are preserved with a deposited software artifact?
- 5.4 What is the codemeta.json file, why should I use it?
- 5.5 Does Software Heritage perform a check on the metadata (e.g. to verify whether a licence is declared)?
- 6. Research Software
- 7. Crediting and software citation
-
8. Legal and financial
- 8.1 Should I put a license on my code before saving it in SWH?
- 8.2 Who owns my data in SWH?
- 8.3 How is the metadata licensed? What are policies about accessing metadata? is it different than accessing content?
- 8.4 How can I remove my code from SWH?
- 8.5 How much should I pay to archive my data in SWH?
- 8.6 Does SWH guaranty any timestamping of code archived in case of legal issue?
- 9. Next steps and long term strategy
- 10. Get involved
-
FAQ Software Heritage (docs)
-
Users
- How can I search the SWH archive? is it possible to search over metadata?
- How are
- Is it possible to do a save request with a link to a .zip or tarball on a website? what file formats are supported with the save code now?
- I tried archiving a repository with the "Save code now" feature. The request seems to be stuck in pending status. what should I do?
- How can I use the SWH dataset?
-
Contributors (devel) DONE (we'll open a diff soon)
- Do I need to sign a form to contribute code?
- Will my name be added to a CONTRIBUTORS file?
- What are the Skills required to be a code contributor?
- What are the must read docs before I start contributing? (System architecture, python module dependency etc)
- Where can I see the getting started guide for developers?
- I have SWH stack running in my local. How do I get some initial data to play around?
- Is there a way to connect to SWH archived (production) database from my local machine?
- I have a SWH stack running in local, How do I setup a lister/loader job?
- I found a bug/improvement in the system, where should I report it?
- How do I find an easy ticket to get started?
- I am skilled in one specific technology, can I find tickets requiring that skill?
- Where should I ask for technical help?
- I found a straightforward typo fix, should my fix go through the entire code review process?
- How can I create a user in my local instance? (web application/Django user)
- Should I run/test the web app in any particular browser?
- What tests I should run before committing the code? (It could be specific to the project)
- I am getting errors while trying to commit. What is going wrong? (Must be pre-commit hooks failing...)
- Is there a format/guideline for writing commit messages?
- How do I generate API usage credentials?
- Is there a page where I can see all the API endpoints?
- What are the usage limits for SWH APIs?
- Contributors (Sys-admin)
-
Users
- Garbage collector
-
New questions to review
-
2022-11-24 Sed Lyon
- Q1 : please, where may i find information on how to take into account the environmental aspects of SWH data storage? How SWH deals with environmental issues?
- Q2: what's the actual size of the archive and which image could be chosen to make the topic less abstract for non-technical audiences ?
- Q3 : where the code is stored ? (different from Q1 that focuses on the impact in terms of resources consumption)
-
2023-04-05 Q&A following Roberto's talk in Lyon
- Q1: What happens if AWS closes?
- Q2: How do you deal with legal aspects? What if a repo contains information that can't be shared?
- Q3: How do you plan the needs in terms of storage?
- Q4: Is there an agreement signed between SWH and the owner of the platform that is harvested? What is the legal framework that allows the regular crawling?
- Q5: The source code in itself isn't always enough. How does SWH provide contextual information about a project?
- Q6: How does SWH deal with the archiving of issues?
- Following HAL training sessions
- Following the MediaNormandie webinar
- Retrieved from the general chat room
- Following the DataCite webinar (2023-05-24)
- Following 2023-06-08 Cirad talk given by Pierre Poulain
- Retrieved from emails with the authors of the Mooc "Reproducible research": use case
-
2022-11-24 Sed Lyon
FAQ Software Heritage (website)
1. General
1.1 What is Software Heritage (SWH)?
Software Heritage is an open, non-profit initiative unveiled in 2016 by Inria. It is supported by a broad panel of institutional and industry partners, in collaboration with UNESCO.
Expand for details
The long term goal is to collect all publicly available software in source code form together with its development history, replicate it massively to ensure its preservation, and share it with everyone who needs it.
For more information about the SWH mission.
1.2 What is the SWH archive?
The SWH archive is the largest public collection of source code in existence. Visit the archive on https://archive.softwareheritage.org.
1.3 What is the size of the archive?
The archive is growing over time as we crawl new source code from software projects and development forges. You can see live counters of the archive contents, as well as a breakdown by crawled origins, on https://archive.softwareheritage.org.
1.4 What are the services provided by SWH?
Software Heritage is a mutualised platform that offers a growing number of services to a large spectrum of users.
The features page provides an overview of the features currently available. This includes, for example, archiving software repositories, browsing the archived source code and providing persistent identification.
2. Archiving software
2.1 Which software platforms (forges, package managers, etc.) are archived?
The software origins that are currently regularly archived are listed on the main archive page.
Expand for details
Here is an excerpt of this list:
- git repositories from multiple forges (github, bitbucket, gitlab instances, cgit instances, gitea instances, phabricator instances, etc.)
- svn repositories...
- mercurial repositories...
- Debian packages in apt
- Python packages in PyPI
- R packages in CRAN
- NPM packages in npm.org
- zip or archives tarballs in gnu.org
2.2 If my code is on GitHub/GitLab/Bitbucket, is it already archived in SWH?
It might be, as we crawl these and other popular forges regularly. Search for your code repository on https://archive.softwareheritage.org/browse/search/.
Expand for details
If it is not there yet, or if the latest snapshot is not the most recent state of your repository, you can trigger a new archival using the Save Code Now functionality https://archive.softwareheritage.org/save/ or by clicking on the "Save again" button in the browse view.

A GitHub action is available to automatically push a save code now request. Here is an example of this action configured to run each time a new release is issued.
You can also use the browser extension.
2.3 If I delete the repository that contains my code, will the data stay in SWH?
Yes, all software source code artifacts are preserved for the long-term.
2.4 What is the policy for determining what deserves to be archived? are there requirements for a GitHub, Gitlab or XXX repository to be archived by SWH?
We do not inspect or filter the source code, and archive anything that we can get hold of. As a consequence, here are no requirements but we do suggest following the SWH guidelines for best results.
Expand for details
The reason for this approach is because the value of software source code cannot be known in advance. When a project starts, one cannot predict whether it will become a key software component or not. For example, when Rasmus Lerdorf released the first version on PHP back in 1995, who could have predicted that it would become one of the most popular tools for the Web.

XKCD Comics https://xkcd.com/2347/ (CC BY-NC 2.5)
And it also happens that very precious pieces of source code may be go unnoticed for decades, until one day some unexpected bug unveils that a big part of our digital infrastructure relies on them.
2.5 Is the code checked for LICENSE file or any specific characteristic in the repository before archiving?
Software Heritage archives everything that is publicly available, without preliminary tests or checks.
This means that you are responsible for checking whether the source code you find in the archive can be reused, and under which terms.
For the code that you produce, we do suggest following standard best practices, that are recalled in the SWH guidelines, and this include adding licensing information.
2.6 Do you also archive software executables (aka binaries)?
Our core mission is to preserve source code, because it is human readable and contains precious information that is stripped out in the executables. As a consequence, we do not actively archive binaries, but if binaries are included in a software repository, we do not filter them out in the archival process. Hence you can find a few binaries in the archive.
2.7 I can't find all my "releases" in a git repository in Software Heritage, what should I do?
Do not worry, your repository has been saved in full. What you are witnessing is just a terminological difference between what platforms like GitHub calls "releases" (any non annotated git tag) and what we call "releases" (a node in the Merkle tree, which corresponds to a git annotated tag). This is a common issue, as you can see for example in this discussion thread.
Expand for details
Let's say you tagged your release naming it "FinalSubmission", but you did not use an annotated tag: in this case, it will not show up in the Releases tab on Software Heritage, but it is there nonetheless! Click on the branch dropdown menu on the Software Heritage Web interface and you'll find it listed as "refs/tags/FinalSubmission". If you want a release to appear in our web interface you should create your tags using "git tag -a", instead of simply "git tag", or create the release directly on the code hosting platform, that uses the proper "git tag -a" behind the scenes, and then archive your repository again.
3. Referencing and identification
3.1 What is a SWHID (Software Heritage Identifier)?
The SWHID (Software Heritage Identifier), is a persistent intrinsic identifier that is computed uniquely from the software artifact itself. See the dedicated blog post to learn more about intrinsic and extrinsic identifiers.
Expand for details
All details about the syntax, semantics, interoperability and implementation can be found in the formal specification.
The following diagram shows concisely the key components of a SWHID:
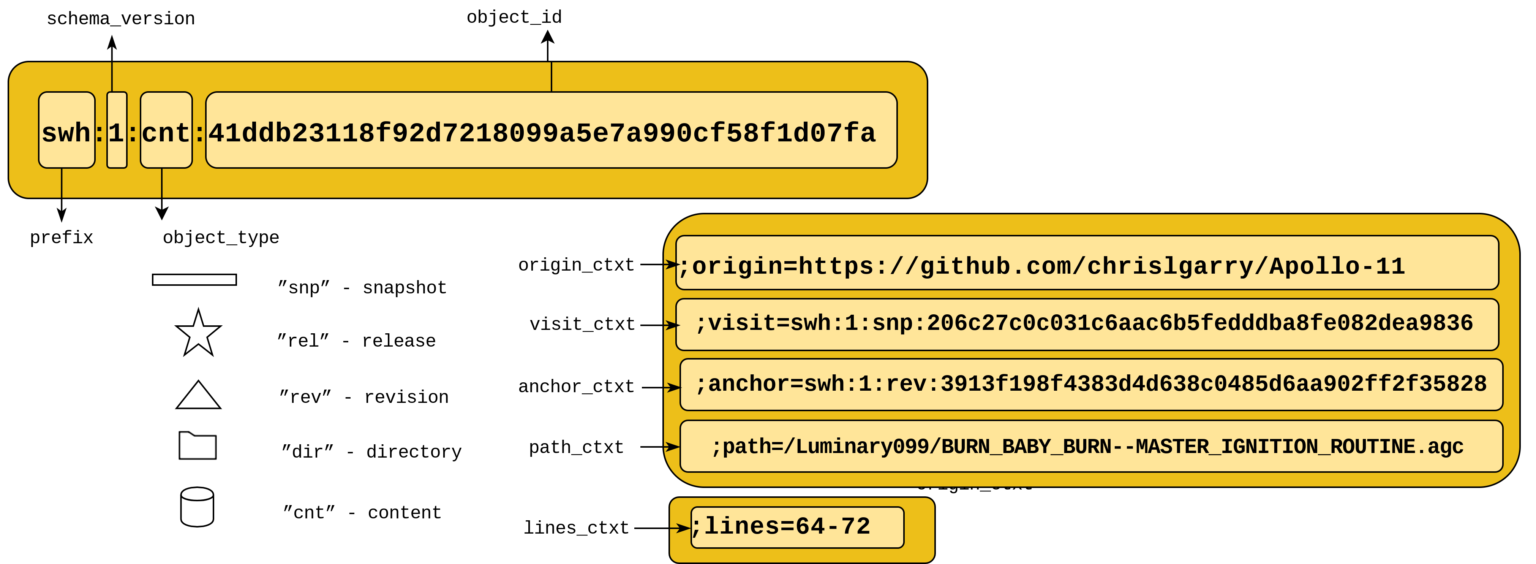
Credit: Software Heritage, 2019
The top yellow box in the diagram corresponds to the "core SWHID". It is possible to add qualifiers to a core SWHID in order to provide additional information about the location of the object in the Software Heritage graph, or its origin, and to identify code fragments.
3.2 What can be identified with a SWHID?
First, let's notice that software can be identified at quite different levels of granularities, ranging from a conceptual level (e.g. the name of a software project), to concrete software artifacts (e.g. a directory containing plenty of files).
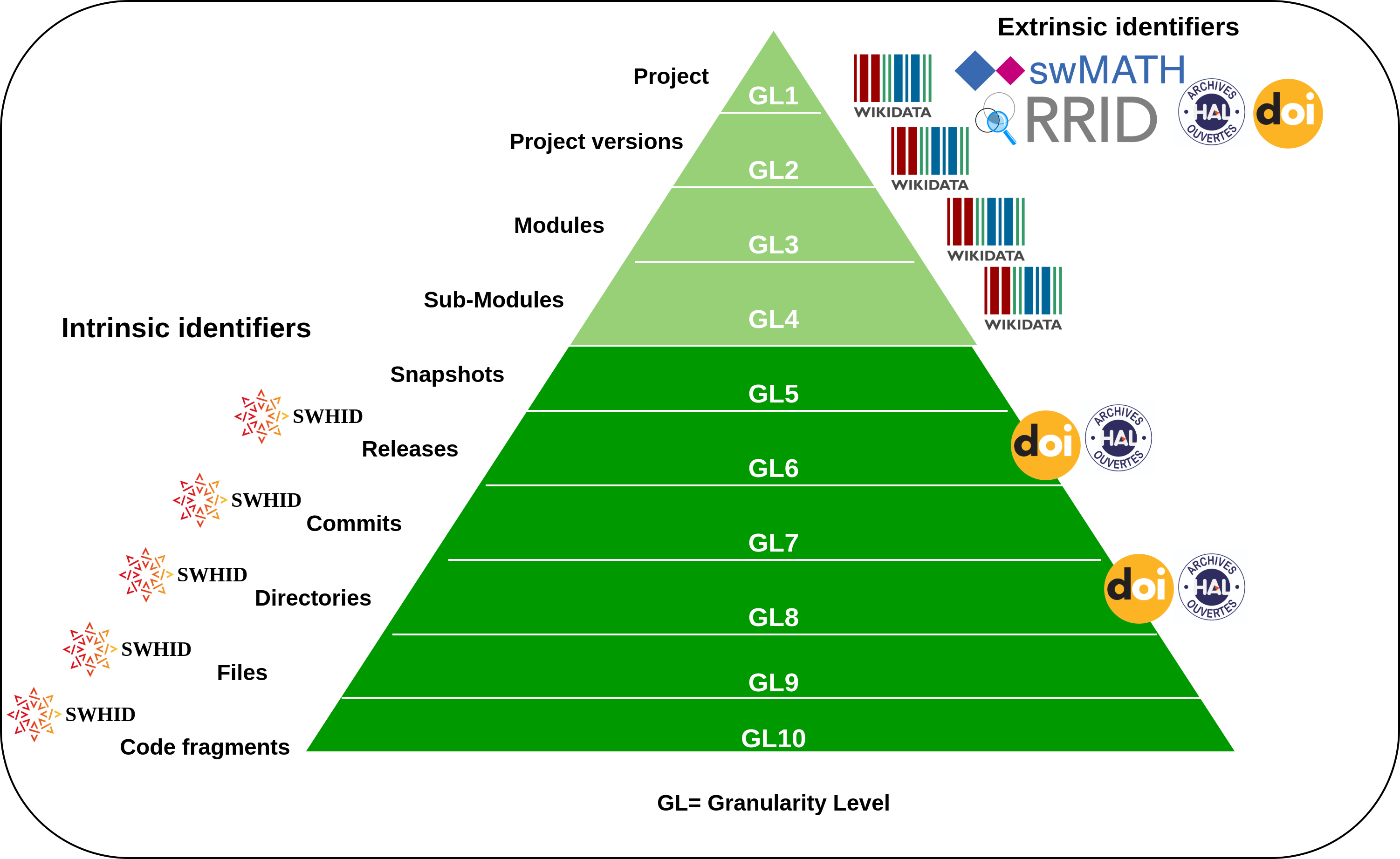
Credit: Research Data Alliance/FORCE11 Software Source Code Identification WG, 2020, https://doi.org/10.15497/RDA00053
The Software Heritage identifiers are designed to identify permanently and intrinsically all the levels of granularity that correspond to concrete software artifacts: snapshots, releases, commits, directories, files and code fragments.
Expand for details
A core SWHID can be used to identify the following source code artifacts:
-
file contents; for example, swh:1:cnt:94a9ed024d3859793618152ea559a168bbcbb5e2 points to the content of a file containing the full text of the GPL3 license
-
directories; for example, swh:1:dir:d198bc9d7a6bcf6db04f476d29314f157507d505 points to a directory containing the source code of the Darktable photography application as it was at some point on 4 May 2017
-
revisions (a.k.a commits); for example, swh:1:rev:309cf2674ee7a0749978cf8265ab91a60aea0f7d points to a commit in the development history of Darktable, dated 16 January 2017, that added undo/redo supports for masks
-
releases; for example, swh:1:rel:22ece559cc7cc2364edc5e5593d63ae8bd229f9f points to Darktable release 2.3.0, dated 24 December 2016
-
snapshots; for example, swh:1:snp:c7c108084bc0bf3d81436bf980b46e98bd338453 points to a snapshot of the entire Darktable Git repository taken on 4 May 2017 from GitHub
Using the "lines" qualifier, it is possible to also identify "code fragments", i.e. selected lines of code.
For example, swh:1:cnt:94a9ed024d3859793618152ea559a168bbcbb5e2;lines=4-6 pinpoint lines 4 to 6 of the full text of the GPL3 license.
More generally, using a fully qualified SWHID provides all relevant information for placing a software artifact in context. For example, the following SWHID pinpoints the core mapping algorithm contained in the file parmap.ml, located in the src directory of a specific revision of the Parmap project retrieved from https://github.com/rdicosmo/parmap
3.3 How can I get a SWHID for my software?
The core SWHID identifier is intrinsic, so yes, you can compute the core SWHID of any software artifact locally on your machine! You can find instructions in the documentation available here!
You can also get the full SWHID for any archived software artifact directly from the Software Heritage archive: using the red vertical tab called "Permalinks", present on every page that shows source code (see this HOWTO for more details). The advantage of this second approach is that you can get a SWHID with relevant contextual information (e.g. the position of your artefact in the global graph of software development).
Expand for details
The "Permalinks" tab let you obtain a SWHID for the content that you are browsing. Here is an example:
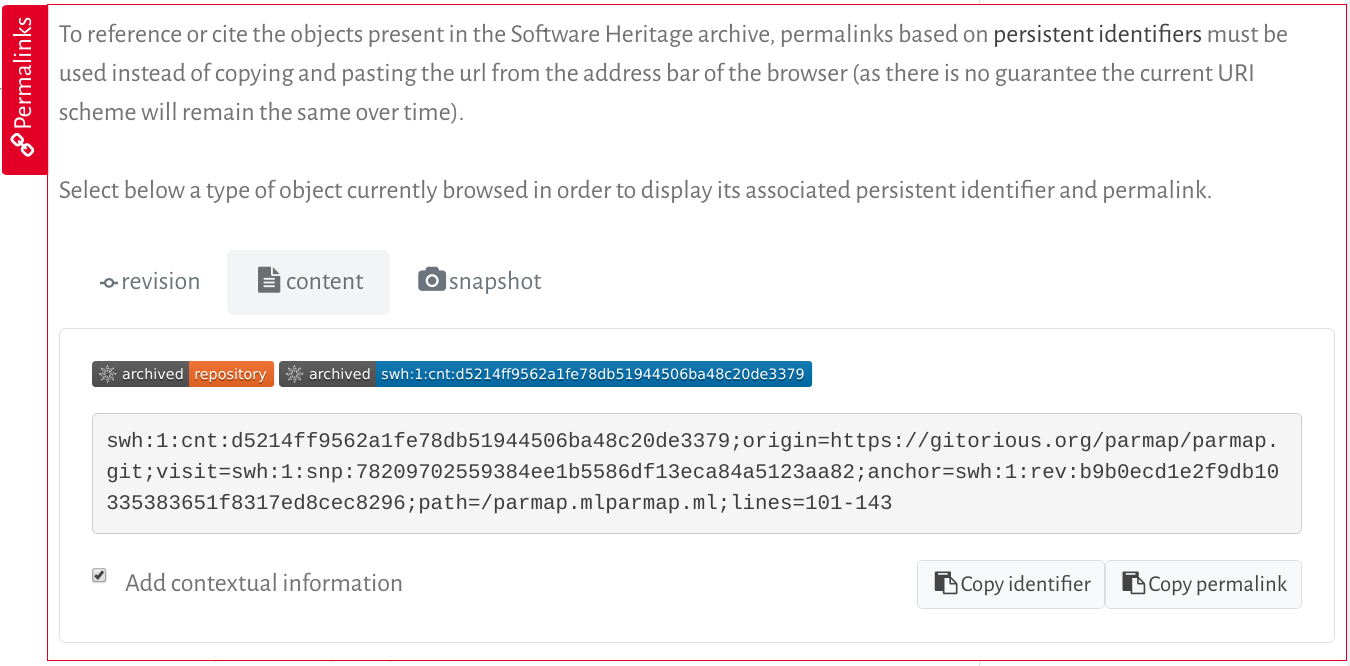
Clicking on "Copy identifier" you can get the SWHID in your clipboard. Clicking on "Copy permalink" you can get in your clipboard the corresponding URL.
The "Add contextual information" checkbox allows you to choose whether you will get a core SWHID or the SWHID with the extra qualifiers that provide contextual information.
Notice that the Permalinks tab offers a plurality of options to pick a SWHID (you may get the one for the file content, the directory that contains it, the revision, the release or the snapshot). See the following question to understand which is best for your use case.
3.4 Which type of SWHID should I use in my article/documentation?
It really depends on your use case, but as a general suggestion we recommend to take the full SWHID of a directory (with the contextual information).
Expand for details
When writing a research article, a blog post or technical documentation, one may face some tension between the need to provide the maximum amount of information, using the full SWHID, or keeping the reference short (for example due to page limitations).
Here is the recommended best practice to address this issue:
-
get the full SWHID for the 'directory' containing the version of the code you want to reference. Here is an example of such a full SWHID:
swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18;origin=https://gitlab.com/lemta-rheosol/craft-virtual-dma;visit=swh:1:snp:ef1a939275f05b667e189afbeed5fd59cca51c9d;anchor=swh:1:rev:ad74f6a7f73c7906f9b36ee28dd006231f42552e -
ensure the "core SWHID" (
swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18in the example above) is printed, and the full SWHID is available at least as an hyperlink.
This effect can be achieved as follows in LaTeX:
\href{https://archive.softwareheritage.org/swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18;origin=https://gitlab.com/lemta-rheosol/craft-virtual-dma;visit=swh:1:snp:ef1a939275f05b667e189afbeed5fd59cca51c9d;anchor=swh:1:rev:ad74f6a7f73c7906f9b36ee28dd006231f42552e/}{swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18}
or in Markdown:
[swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18](https://archive.softwareheritage.org/swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18;origin=https://gitlab.com/lemta-rheosol/craft-virtual-dma;visit=swh:1:snp:ef1a939275f05b667e189afbeed5fd59cca51c9d;anchor=swh:1:rev:ad74f6a7f73c7906f9b36ee28dd006231f42552e/)
This approach ensures that in any printed version the reader will find the identifier that is most useful for reproducibility: the core SWHID of the directory. Indeed, the core SWHID of a directory can be locally computed from any instance of a source code, independently of the release or commit that cointains it in a specific project.
In the digital version the clickable link uses the full SWHID to let the reader browse the code in Software Heritage with all the proper context (version, origin, etc. etc.).
3.5 I want the full SWHID for a source code that is not already in the archive. How can I proceed? How long will it take?
If your code (or the latest version of it) is not yet in the archive, you need first to trigger its archival. This can be done with a "Save Code Now" request, or via the deposit API.
Once a Save Code Now request is issued, the ingestion of the code is usually completed in a few minutes, depending on the size of the repository. Once it's done, the status of the save request is updated and you can get the SWHID as shown before.
When a deposit is submitted, the ingestion is also usually completed in a few minutes and the SWHID is accessible through the SWORD status response.
4. Access and Reuse
4.1 Can I reuse the source code artifacts I find on SWH?
It depends on the license of the artifact, as stored alongside the source code: you must check this license before downloading or reusing it. If you cannot find the license information, you should assume that you have no right to reuse it.
Expand for details
All software components present in the Archive may be covered by copyright, or other rights like patents or trademarks. Software Heritage may provide automatically derived information on the software license(s) that may apply to a given software component, but it makes no claim of correctness and the licence information provided does not constitute legal advice. You are solely responsible for determining the license, or other rights that apply to any software component in the Archive, and you must abide by its terms.
4.2 Can I clone a repository using SWH?
Please do not clone a full repository directly from SWH: it is an archive, not a forge. Try first to clone a repository from the place where it is developed: it will be faster and as an added bonus you will be already in the right place to interact with its developers.
Expand for details
SWH stores all the software artifacts in a massive shared Merkle tree, so that exporting (a specific version of) an archived respository implies traversing the graph to get all the relevant contents and packaging them up for your consumption. This operation is much more expensive than downloading an existing tar file or cloning a repository from a forge.
If really SWH is your last resort, and you cannot find the source code of interest elsewhere, we recommend that you download only the version of interest for you, using the "directory" option of the Download button that you find when you browse the archive.
If absolutely needed, you can use the more expensive "revision" option of the Download button, that will prepare for you the equivalent of a git bare clone , which you will be able to use offline. This may require quite some time (hours, or even days for huge repositories).
4.3 Can I retrieve a source code artifact through the API?
Yes, you can. If you have the SWHID at hand, you can use the appropriate API method for it to navigate through the endpoints to follow the graph of project artifacts. Checkout the API documentation for the complete list of endpoints.
Expand for details
-
/api/1/snapshot/ which allows you to get the snapshot's branches and tags, each with a
target_urlkey that contains the URL to -
/api/1/release/ or /api/1/revision/ which allow you to get the revision's or releases' data. Assuming you get a revision, the
directory_urlkey contains a URL to: - /api/1/directory/ which lists entries of the root directory, with links to other directories and content objects
- /api/1/content/ which returns all the information about a given file content, including a link to the raw data.
You can also lookup an origin, and follow its visits:
- /api/1/origin/search/ allows you to search the exact URL of the code repository
-
/api/1/origin/visits/ allows you to list the times Software Heritage visited the repository, and get the snapshot associated with each visit. For each visit, this snapshot is available as a
snapshot_urlkey, that contains the URL to get the corresponding snapshot object.
If you are interested in downloading a large part of the repository (a directory or a set of revisions), you should use the download service called the Vault. The Vault allows you to fetch them in batch and download a tarball. The list of vault endpoints is available at the end of the list of all API endpoints
5. Software metadata
5.1 Can I add metadata to my software?
A regular user can add metadata files in the repository which will be ingested and indexed when using a specific file format (codemeta.json, package.json, pom.xml, etc.).
Expand for details
Follow the SWH guidelines on how to prepare your code for archival.
More information about the formats that are indexed and some general overview of the metadata workflow in the blog-post about mining for software metadata
5.2 What metadata are preserved from a code repository, with save code now?
All metadata contained by the source code repository itself is preserved. This will include the development history and commit dates and messages. At the moment, other metadata artifacts which are not part of the repository (known as extrinsic metadata) are not preserved when using the Save Code Now feature.
5.3 What metadata are preserved with a deposited software artifact?
All metadata which is sent via the SWORD protocol accompanying the software artifact. For more information visit the deposit documentation.
5.4 What is the codemeta.json file, why should I use it?
As software developers, we may want to provide a machine readable description of our projects, but there are (too) many metadata schemas for describing software, and one can easily get lost.
The CodeMeta initiative created a common vocabulary to address this issue, based on (a slight extension of) the SoftwareApplication and SoftwareSourceCode classes of the well established schema.org initiative, and provides tools to convert back and forth from other medatada schemas.
The codemeta.json file is a JSON-LD representation of the CodeMeta vocabulary, that can be easily created and validated using the Open Source codemeta generator tool. By adding a codemeta.json file to your project, you make it easy to share metadata information, and reduce the burden of retyping a lot of information in data entry forms.
Expand for details
For example, the french HAL national open access archive looks for a codemeta.json file when a software project archived in Software Heritage is deposited, and pre-fills the deposit form using the information it contains, a real time saver!
Last but not least, Software Heritage indexes the metadata contained in codemeta.json files and makes it searchable on the web-app using the CodeMeta crosswalk table. The crosswalk table is the Rosetta stone of software metadata, facilitating translation between ontologies and metadata standards for software.
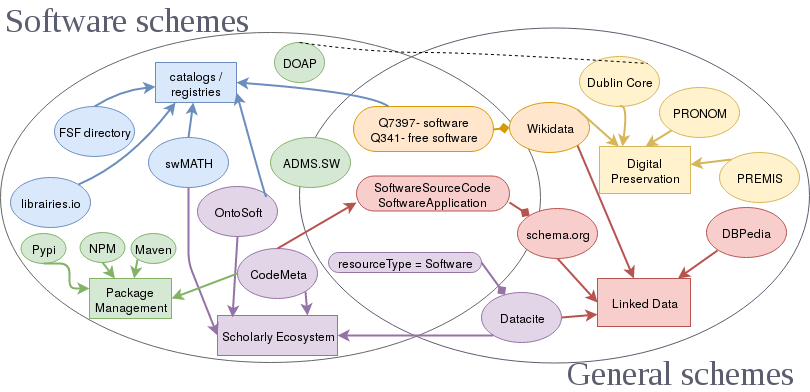
Credit: Gruenpeter M. and Thornton K. (2018) Pathways for Discovery of Free Software (slide deck from LibrePlanet 2018). https://en.wikipedia.org/wiki/File:Pathways-discovery-free.pdf
5.5 Does Software Heritage perform a check on the metadata (e.g. to verify whether a licence is declared)?
The short answer is no. Software Heritage does not perform any a priory filtering of the repositories that are archived.
:::danger [verified by Roberto up to here] :::
6. Research Software
6.1 My code is archived in Zenodo, should I also archive the source code in Software Heritage?
Yes, archiving in SWH is complementary to archiving on Zenodo.
There are a few differences between archiving software on Zenodo and on SWH.
-
Software Heritage archive all development history, including all commits and releases on all branches while Zenodo archives only the releases (with the GitHub-Zenodo integration) or a directory with the deposited code.
-
Software Heritage can preserve development history from different VCS systems (git, mercurial, svn) and from different development platforms (GitHub, Gitlab, Bitbucket, etc.)
-
Metadata on Zenodo is not curated or moderated, while on HAL (archives-ouvertes.fr), there are moderators that verify that the metadata is accurate for the deposited source code. The source code deposited on HAL is transferred to SWH alongside the deposited metadata.
6.2 My data are in a GitHub repository. Can I archive them with SWH?
Let's distinguish two cases here. It is of course ok to archive in SWH source code repositories that also contain data needed for the software development (e.g. test data).
On the other hand, you should not rely on SWH to archive repositories that contain just a big set of data files (e.g. a collection of csv file).
Software Heritage is an archive for source code, and it is not designed to handle datasets: you are much better off using a data archive that can handle large datasets and provides means to make them discoverable.
We currently do not filter out these cases, so, technically, you can trigger archival of such a repository, but the policy may evolve in the future.
Note that git based platforms, like GitHub, do not allow objects that exceed 100MB are not allowed, and SWH enforces the same limits.
To avoid disappointments, use data archive to archive data.
6.3 Why don’t you provide DOIs?
Intrinsic identifiers like the SWHID and extrinsic identifiers like the DOI are complementary and answer different identification use-cases, see the related question on SWHIDs, and this analysis of the differences between Intrinsic and Extrinsic identifiers.
Software Heritage is designed to archive source code, and like all modern code hosting plaforms it uses intrinsic identifiers that are more appropriate for software artefacts than extrinsic identifiers like DOIs.
6.4 What are the best practices to use SWH?
Checkout the guidelines https://www.softwareheritage.org/save-and-reference-research-software/
https://www.softwareheritage.org/howto-archive-and-reference-your-code/
7. Crediting and software citation
(preliminary draft of howto cite software with swh https://hedgedoc.softwareheritage.org/Cj63ErI8SvWXkIVQYazQRg?both)
7.1 Why should I cite software? and why should I use Software Heritage to do so?
-
why?
- proper credits to the author
- forces you to double check your sources (avoid plagiarism)
- gives pointers to the people reading the paper who wants to dig in further
-
why swh?
- objectivity -> no hard dependency on swh to actually compute the SWHID
- reproducibility -> uses intrinsic id that can be computed by any other entity than swh -> people can retrieve the source code even if it disappeared from the main forge using swh archive as fallback
7.2 Who should I cite if I retrieve some code from SWH?
Citing is way to acknowledge the authors and give credit to their work, which is different than referencing a piece of source code needed for reuse or reproducibility. Therefore, you should search for the authors of the artifact and cite them.
Deposit code on HAL or other academic platform To get credit for the work done on a piece of software, it should be deposited on HAL which provides a full citation, BibTeX export and codemeta.json export. Also all metadata is verified by a moderator to validate that the all authors mentioned in source code are given the credit on the HAL record.
If you can't find the a deposit attached to the source code (on which a citation is available), you can check the source code for codemeta.json, citation.cff, authors or other metadata files to have the list of authors. Some projects give specific information on the README on how to cite the project. Keep in mind to use the SWHID to reference the specific code
7.3 I’d like to cite my code archived in SWH. How do I do that?
TODO:
- cite in your README file on GitHub or Gitlab → badge https://www.softwareheritage.org/2020/01/13/the-swh-badges-are-here/
- cite in a paper: LaTeX package Roberto + F1000 Research paper.
7.4 Should I cite SWH or the author of the code?
Software Heritage acts as an achive provider and should not be listed as author of the software. However, we should systematically add a SWHID along the reference if available.
Bibliography style:
Blog post: https://www.softwareheritage.org/2020/05/26/citing-software-with-style/
Examples From Sample of citations: https://ctan.gutenberg.eu.org/macros/latex/contrib/biblatex-contrib/biblatex-software/sample-use-sty.pdf
[Software] T. Gally, G. Gamrath, P. Gemander, A. Gleixner, R. Gottwald, G. Hendel, C. Hojny, S. J. Maher, M. Miltenberger, B. M¨uller, M. Pfetsch, F. Schl¨osser, F. Serrano, S. Vigerske, D. Weninger, and J. Witzig, SCIP, swmath: hswmath:01091i.
[Software] R. Di Cosmo and M. Danelutto, The Parmap library version 1.1.1, 2020. Inria, University of Paris, and University of Pisa. vcs: https://github.com/rdicosmo/parmap.
[Software Module] M. Karavelas, “2D Voronoi Diagram Adaptor”, part of The Computational Geometry Algorithms Library version 5.0.2 (Coordinated by CGAL Editorial Board), 2020. swhid: swh:1:rel:636541bbf6c77863908eae744610a3d91fa58855;origin=https ://github.com/CGAL/cgal/.
[Software Release] The CGAL Project, The Computational Geometry Algorithms Library version 5.0.2 (Coordinated by CGAL Editorial Board), 2020. swhid: swh:1:rel:636541b bf6c77863908eae744610a3d91fa58855;origin=https://github.com/CGAL/cgal/.
[Software excerpt] R. Di Cosmo and M. Danelutto, “Core mapping routine”, from The Parmap library version 1.1.1, 2020. Inria, University of Paris, and University of Pisa. vcs: https://github.com/rdicosmo/parmap, swhid: h swh:1:cnt:43a6b232768017b03da934b a22d9cc3f2726a6c5;lines=192-228;origin=https://github.com/rdicosmo/parmapi.
[Rp] Reproducing and replicating the OCamlP3l experiment ReScience C, 6 (1), 2020 https://doi.org/10.5281/zenodo.4041602

Related references
-
European Commission. Directorate General for Research and Innovation. (2020). Scholarly infrastructures for research software: report from the EOSC Executive Board Working Group (WG) Architecture Task Force (TF) SIRS. Publications Office. https://doi.org/10.2777/28598
-
Pierre Alliez, Roberto Di Cosmo, Benjamin Guedj, Alain Girault, Mohand-Said Hacid, Arnaud Legrand, Nicolas Rougier Attributing and Referencing (Research) Software: Best Practices and Outlook From Inria Computing in Science Engineering, 22 (1), pp. 39-52, 2020, ISSN: 1558-366X. https://hal.archives-ouvertes.fr/hal-02135891 https://dx.doi.org/10.1109/MCSE.2019.2949413
- roles in software development
- complexity of software / granularity
-
Research Data Alliance/FORCE11 Software Source Code Identification WG, Allen, Alice, Bandrowski, Anita, Chan, Peter, di Cosmo, Roberto, Fenner, Martin, … Todorov, Ilian T. (2020, October 6). Software Source Code Identification Use cases and identifier schemes for persistent software source code identification (Version 1.1). http://doi.org/10.15497/RDA00053
8. Legal and financial
#website
8.1 Should I put a license on my code before saving it in SWH?
It is recommended but not checked nor enforced.
8.2 Who owns my data in SWH?
8.3 How is the metadata licensed? What are policies about accessing metadata? is it different than accessing content?
8.4 How can I remove my code from SWH?
Use case: scientists are not really aware of intellectual policy and may publish some code by error on GitHub. Now the repository has then been archived in SWH, how can they ask us to take it down?
The legal procedure is in place to verify the take down request with a legal responsible Inria (JDPO?). It is possible legally, if a motive to take down the source code is provided. The procedure is the following:
- checking the identity for the received request
- checking the license under which the source code was released
- if the request passes the legal procedure it will be removed from the archive technically
For more information on how to send a request here: https://www.softwareheritage.org/legal/content-policy/
8.5 How much should I pay to archive my data in SWH?
Archiving your code in SWH in totally free at point of use. SWH is a non profit organization, and runs on funding provided by sponsors and members. If you work for an organisation that can contribute to the mission of Software Heritage, please consider proposing it to become a sponsor or member (see https://www.softwareheritage.org/support/sponsors/program). Individual donations are welcome too (see https://www.softwareheritage.org/donate)
8.6 Does SWH guaranty any timestamping of code archived in case of legal issue?
See the Visits tab.

9. Next steps and long term strategy
9.1 Where can I find the SWH roadmap?
The roadmap is accessible on the docs. Here is the link to the 2021 roadmap.
TODO: check long-term goals and see if it can be documented
9.2 is SWH sustainable?
9.3 What is a SWH mirror?
A mirror is a full copy of the entire Software Heritage archive, run by an independent organization. The mirror network ensures the archive survives failures of any individual organization.
9.4 How can my organization mirror SWH?
9.5 What is the time guarantee for the SWH archive?
9.6 How does SWH integrate with other preservation strategies?
preservation strategies (emulation, migration, etc.) - pulling it back out? how? can it be used in the future? - what will be possible to do with the software in the future
10. Get involved
10.1 How do I get in touch with the team?
Here are a few options:
- contact form for any enquiries
- scholar/scientific mailing list and working groups
- development channels
- users mailing list and community
10.2 Can I get an internship? How? Can I get an open position at SWH?
Yes! See the internship list and contact the main mentor, or use the contact form.
Open positions are listed on our Jobs page
10.3 How can I become an ambassador?
10.4 How can I become a sponsor?
10.4.1 Are there ressources to advocate SWH to my organization?
FAQ Software Heritage (docs)
Users
https://docs.softwareheritage.org/users/faq/index.html TODO: compare text below and complete
How can I search the SWH archive? is it possible to search over metadata?
At the moment searching is possible using the url of a repository, package or deposit (a.k.a the origin of the source code). You can use the checkbox "search in metadata (instead of URL)" to search over intrinsic metadata.

How are
code now requests handled? one-time or recurrent? human-moderated or automated? #docs-users
Save code now requests on known forges for origins are scheduled as soon as possible. Unknown origins are put in a moderation queue waiting for human vetting (Ambassadors or staff).
Is it possible to do a save request with a link to a .zip or tarball on a website? what file formats are supported with the save code now?
#docs-users #website?
For ambassador, it is possible to do save code now requests on zip or tarballs with the visit type 'archives'.
The save code now is intended publicly only for code repositories with git, mercurial or svn version control systems. (Not yet announced maybe?) Ambassadors, however can also deposits for a given origins multiple artifacts (zip, tarballs).
I tried archiving a repository with the "Save code now" feature. The request seems to be stuck in pending status. what should I do?
GitHub repositories are be saved without approval, so if your repository is on GitHub, this should not last more than a few hours. If your repository is not on GitHub, requests should be approved within a few days (minus French bank holidays), and loaded in a few hours.
If your repository is still pending after this time, this is most likely a bug. Get in touch with us to check we are aware of this bug and are working on it.
I was thinking about the problem in my local instance (I tried importing data from SWH forge and it got stuck).This answers that problem as well. Can we add some detail about approving the pending request in local instance? (maybe by approving as an admin user, I aslo think user "ambassidor" can save any forge)[JV] I agree that text about this in the local instance is needed, not sure if it should be in the FAQ [MG]
How can I use the SWH dataset?
TODO: quick start guide (Athena)
Contributors (devel) DONE (we'll open a diff soon)
https://docs.softwareheritage.org/devel/faq/index.html
requisite:
- one page with all questions sorted by categories
- from the menu, "FAQ" > list of categories > click on category > dropped into the same page with internal link on the dedicated category
Idea for categories:
- Prerequisites
- getting started
- running SWH instance
- Getting help (e.g Finding a task, i'm stuck with testing, ...)
- API?
- Errors & bugs
- Code review (e.g commits, diff, ...)
- Packaging (should be in sys-admin- but until we have a dedicate place let's keep here)
- Legal
- dataset
Do I need to sign a form to contribute code?
#Legal
Yes, on your first diff, you will have to sign such document. As long as it's not signed, your diff content won't be visible.
Will my name be added to a CONTRIBUTORS file?
#Legal
You will be asked during review to add yourself.
What are the Skills required to be a code contributor?
#prerequisite
It depends on what area you want to work on. Internships postings list specific skills required. Generally, only Python and basic Git knowledge are required. Feel free to contact us on one of the development channels for details.
What are the must read docs before I start contributing? (System architecture, python module dependency etc)
#getting-started
We recommend you read the top links listed at from the documentation home page in order: getting started, contributing, and architecture, as well as the data model.
Where can I see the getting started guide for developers?
#getting-started
At the top of the documentation home page
I have SWH stack running in my local. How do I get some initial data to play around?
#running-swh-instance The Docker environment documentation details how to run a lister, which you can run on a small forge to load some repositories from this forge.
Isn't it easier to get some initial data with "Save code now"? [JV]
Is there a way to connect to SWH archived (production) database from my local machine?
#dataset
We provide the archive as a dataset on public clouds, see the swh-dataset documentation. We can also provide read access to one of the main databases on request; contact us.
I have a SWH stack running in local, How do I setup a lister/loader job?
#running-swh-instance
See the Docker environment documentation
I found a bug/improvement in the system, where should I report it?
#error-bugs
Please report it on our bug tracking system. First create an account, then create a bug report using the "Create task" button. You should get some feedback within a week (at least someone triaging your issue). If not, get in touch with us to make sure we did not miss it.
How do I find an easy ticket to get started?
#getting-started
We keep a list of easy tickets to work on, see the Easy hacks page
I am skilled in one specific technology, can I find tickets requiring that skill?
#getting-started
Unfortunately, not at the moment. But you can look at the Internship list to look for something matching this skill, and this may allow you to find topics to search for in the bug tracking system.
Either way, feel free to contact our developers, we would love to work with you.
Where should I ask for technical help?
#getting-started
Use either contact form for any enquiries or one of the development channels.
I found a straightforward typo fix, should my fix go through the entire code review process?
#code-review
You are welcome to drop us a message at one of the development channels, we will pick it up and fix it so you don't have to follow the whole code review process.
How can I create a user in my local instance? (web application/Django user)
#running-swh
Assuming docker environment here, we cannot. Stay either anonymous or use the user "test" (password "test") or the user ambassador (password "ambassador").
Note: We could but it's not yet a simple process... (docker-compose.override.yml, trigger docker-compose with keycloak...) and then https://forge.softwareheritage.org/D5882
Should I run/test the web app in any particular browser?
#running-swh
We expect the web app to work on all major browsers. It uses mostly straightforward HTML/CSS and a little Javascript for search and source code highlighting, so testing in a single browser is usually enough.
What tests I should run before committing the code? (It could be specific to the project)
#code-review
Mostly run tox (or pytest) to run the unit tests suite. When you will propose a patch in our forge, the continuous integration factory will trigger a build.
I am getting errors while trying to commit. What is going wrong? (Must be pre-commit hooks failing...)
#code-review
Ensure you followed the proper guide to setup your environment and try again. If the error persists, you are welcome to drop us a message at one of the development channels
Is there a format/guideline for writing commit messages?
#code-review See the Git style guide
How do I generate API usage credentials?
#api
See the Authentication guide.
Is there a page where I can see all the API endpoints?
#api
See the API endpoint listing page.
What are the usage limits for SWH APIs?
#api
Maximum number of permitted requests per hour:
- 120 for anonymous users
- 1200 for authenticated users
It's described in the rate limit documentation page.
Contributors (Sys-admin)
SWH releases
Q: How does SWH release?
#sysadm
Release is mostly done:
- first in docker (somewhat as part of the development process)
- secondly packaged and deployed on staging (mostly)
- thirdly the same package is deployed on production
Q: Is there a release cycle?
#sysadm
When a functionality is ready (tests ok, landed in master, docker run ok), the module is tagged. The tag is pushed. This triggers a packaging build process. When the package is ready, depending on the module [1], sysadms deploy the package with the help of puppet.
[1] swh-web module is mostly automatic. Other modules are not yet automatic as some internal state migration (dbs) often enters the release cycle and due to the data volume, that may need human intervention.
Q: git branching strategy?
#code-review
It's left at the developer's discretion. Mostly people hack on their feature, then propose a diff from a git branch or directly from the master branch. There is no imperative. The only imperative is that for a feature to be packaged and deployed, it needs to land first in the master branch.
Garbage collector
This section contains material no longer used in the FAQ but that may torn out handy later on.
PHP history
As an example, consider what Rasmus Lerdorf did when sharing the first version of PHP in 1995 [citation needed] which is now the most popular web programming language.
- original message on mailing list: https://groups.google.com/g/comp.infosystems.www.authoring.cgi/c/PyJ25gZ6z7A/m/M9FkTUVDfcwJ
- There is no access to the code from there
- PHP history: https://www.php.net/manual/en/history.php.php
- On web design museum: https://www.webdesignmuseum.org/web-design-history/php-1-0-1995
Docs todos
TODO: tutorial choosing a SWHID
DOIs
As stated by RFC 3650 'Handle System Overview', that describes how DOI works:
While an existing name, or even a mnemonic, may be included in a handle for convenience, the only operational connection between a handle and the entity it names is maintained within the Handle System. This of course does not guarantee persistence, which is a function of administrative care.
New questions to review
2022-11-24 Sed Lyon
Q1 : please, where may i find information on how to take into account the environmental aspects of SWH data storage? How SWH deals with environmental issues?
or any topic related to resource consumption choices for storage?
Q2: what's the actual size of the archive and which image could be chosen to make the topic less abstract for non-technical audiences ?
Q3 : where the code is stored ? (different from Q1 that focuses on the impact in terms of resources consumption)
The main archive is in a datacenter at Inria headquarters in Rocquencourt. There are copies on AWS (us-east1) and Azure (eu-west). We are working on having mirrors hosted by partners.
2023-04-05 Q&A following Roberto's talk in Lyon
The questions that already are included in the public FAQ are not reported here.
Q1: What happens if AWS closes?
Q2: How do you deal with legal aspects? What if a repo contains information that can't be shared?
Q3: How do you plan the needs in terms of storage?
Q4: Is there an agreement signed between SWH and the owner of the platform that is harvested? What is the legal framework that allows the regular crawling?
Q5: The source code in itself isn't always enough. How does SWH provide contextual information about a project?
Q6: How does SWH deal with the archiving of issues?
Following HAL training sessions
Q1: On HAL, it's easy to link 2 versions of a software. What about SWH? Where can I see the articulation between these different versions on SWH interface?
Following the MediaNormandie webinar
Q1: Why did you choose to interface SWH with HAL rather than another platform (such as RechercheDataGouv)?
Q2 : What's the SWH budget model ?
Retrieved from the general chat room
If I submit a git repo that isn't on one of the known forges, will SWH periodically refresh it? or only fetch it once?
It should be refreshed periodically.
Following the DataCite webinar (2023-05-24)
Q1: What are the biggest shortcomings (features) that publishing platforms have?
Q2: Are speakers participants aware of plans to implement desirable practices in open publishing platforms, such as OJS or ResearchEquals ?
Following 2023-06-08 Cirad talk given by Pierre Poulain
-
Q : Utiliser l'idée du SWHID pour identifier aussi des jeux de données "mouvants"
-
Q : Possibilité de mettre l'équivalent d'un "robot.txt" à la racine d'un dépôt si on souhaite refuser l'archivage d'une partie d'un dépôt (un répertoire par exemple).
R : dans la mesure où SWH récupère tout l'historique du projet -> non
- Q : SWH peut-il être utilisé pour construire de grands modèles de langages (comme l'a fait par exemple GitHub pour Copilot) ? R : a priori non. Roberto: Techniquement, rien n'empêche de faire cela, mais on peut en reparler de vive voix.
Retrieved from emails with the authors of the Mooc "Reproducible research": use case
Description of the need:
"Bonjour Roberto,
[...] Dans le module 1, nous mettons en avant les archives et les identifiants pérènes et en particulier SWH et les swhid. Nous insistons ainsi sur l'importance d'archiver son code et de le référencer comme il faut dans ses articles. Et c'est parfait pour son propre code. Ceux qui veulent l'utiliser pourront effectivement le trouver sur SWH et le télécharger.
En revanche, comme nous mettons également en avant l'intérêt d'automatiser, mettons nous dans la peau d'une chercheuse (pour changer! n'utilisant pas (encore GUIX et qui souhaiterait construire sur deux autres codes. De base, elle aurait mis deux wget (ou deux git clone avec le bon sha1 ou ...) dans son Makefile pour les récupérer de github ou de netlib. Mais c'est le "mal" car on n'est pas sûr de la pérénité de ces URLs et elle préférerait donc utiliser des SWHID. Comment faire en pratique ? En effet, j'ai l'impression qu'il est difficile de faire un wget sur SWH. On a bien vu le code dans GUIX qui passe par SWH quand il ne trouve pas ses sources, et ça marche super bien, mais c'est un peu hardcore pour une chercheuse "lambda". Cette dernière risque vite de se décourager et d'archiver les deux logiciels sur Zenodo histoire que son script puisse les télécharger directement, et ce n'est pas vraiment ce que l'on veut encourager.
As-tu une idée sur la bonne façon de procéder ? Je comprends bien que SWH n'ait pas vocation à se substituer aux plates-formes classiques en terme d'accès à la donnée et que ça impliquerait une augmentation de la charge sur vos serveurs non négligable et non désirable.
Du coup, on s'est aussi demandés s'il serait absurde que SWH fournisse (quand il le peut) un service qui transforme un SWHID en un lien où les données peuvent être téléchargées (chez github, gitlab, etc.), charge à l'utilisateur de vérifier qu'il récupère bien ce qu'il faut, bien sûr.
À bientôt, Arnaud"
Answers: Roberto Voici la partie de la spec qui en parle: (et la version archivée dans SWH) :-) Note on compatibility with Git
SWHIDs for contents, directories, revisions, and releases are, at present, compatible with the way the current version of Git proceeds for computing identifiers for its objects. The <object_id> part of a SWHID for a content object is the Git blob identifier of any file with the same content; for a revision it is the Git commit identifier for the same revision, etc. This is not the case for snapshot identifiers, as Git does not have a corresponding object type.
Git compatibility is practical, but incidental and is not guaranteed to be maintained in future versions of this standard, nor for different versions of Git.
-- Roberto
On Mon, 2 Oct 2023 at 10:55, Roberto Di Cosmo roberto@dicosmo.org wrote:
> Je peux voir que l'origine est GitHub, mais je n'ai pas le commit ID dont j'aurais besoin (parce que je ne suis pas censé savoir que le hash après :rev: est aussi le commit ID de git).
Mais si, mais si, tu est censé le savoir, c'est meme ecrit dans la spec officielle ;-)
--
Roberto
------------------------------------------------------------------
Computer Science Professor
(on leave at INRIA from IRIF/Université Paris Cité)
Director
Software Heritage https://www.softwareheritage.org
INRIA http://y2u.be/Ez4xKTKJO2o
Bureau C328 E-mail : roberto@dicosmo.org
2, Rue Simone Iff Web page : http://www.dicosmo.org
CS 42112 Twitter : http://twitter.com/rdicosmo
75589 Paris Cedex 12 Tel : +33 1 80 49 44 42
------------------------------------------------------------------
GPG fingerprint 2931 20CE 3A5A 5390 98EC 8BFC FCCA C3BE 39CB 12D3
On Mon, 2 Oct 2023 at 09:09, Konrad Hinsen <konrad.hinsen@cnrs.fr> wrote:
Bonjour Roberto,
Merci pour ta réponse détaillée malgré les pressions de la rentrée !
> Idealement, l'outil devrait etre une sorte de "drop in replacement"
> pour un wget (on pourrait l'appeler shwget ou un truc comme c,a :-))
> qui ferait a minima la chose suivante:
...
J'ai pensé à quelque chose de ce genre aussi, et il me semble que ça
devrait même être assez facile à faire, en récupérant le code dans Guix.
"Assez facile" bien sûr à interpréter dans le contexte d'un projet
logiciel !
Pour moi, la question de fonds n'est pas l'outil mais les bonnes
pratiques à recommander aux chercheurs. C'est ça notre rôle fondamental
avec le MOOC.
On était parti sur l'idée de dire "citez votre code par le SWHID".
Mais avec rien que le SWHID, on ne peut pas récupérer l'URL d'origine.
Même la version contextualisée ne suffit pas.
Exemple :
https://archive.softwareheritage.org/swh:1:dir:41b80800574b39aa7143b1f4257bc8afdc014333;origin=https://github.com/khinsen/rescience-ten-year-challenge-paper-4;visit=swh:1:snp:65fc8b9f2c517c0450322ec85becdf2ee6064900;anchor=swh:1:rev:5c232547efd1de14ad3268946e8dcbcd6d12283c
Je peux voir que l'origine est GitHub, mais je n'ai pas le commit ID
dont j'aurais besoin (parce que je ne suis pas censé savoir que le hash
après :rev: est aussi le commit ID de git).
Inversement, si je cite dans mon papier l'URL de GitHub et le commit,
je peux obtenir le code par GitHub, et aussi le retrouver chez SWH
le jour ou GitHub est en panne.
Question provocatrice : à quoi ça sert alors de citer le SWHID ?
Je sais bien que ça donne des infos supplémentaires, parfois utile, mais
est-ce que cette utilité est suffisante pour recommander une pratique
plus lourde et plus à risque d'erreurs ?
A bientôt,
Konrad.Roberto: Bonsoir Arnaud, desole pour la reponse tardive, on est bien sous pression, comme l'on se doit lors d'une rentree :-)
Je vois tout à fait ton use case, et AMHA cela se prete bien au developpement d'un petit outil qui implemente le mechanisme de fallback sur SWH prévu dans guix/nix.
Idealement, l'outil devrait etre une sorte de "drop in replacement" pour un wget (on pourrait l'appeler shwget ou un truc comme c,a :-)) qui ferait a minima la chose suivante:
- essayer de telecharger depuis l'URL normale
- en cas d'échec, faire un fallback sur SWH, en utilisant l'API pour le "Vault", i.e.: https://archive.softwareheritage.org/api/1/vault/flat/doc/ pour demander la préparation de l'archive, et en implementant toute la logique necessaire pour "attendre" que l'archive soit pret avant de le telecharger
A noter qu'on garde un cache pour le vault, donc une fois que le .tar.gz est fabrique, les demandes suivantes vont aller vite tant qu'il reste dans le cache.
Pour que cela fonctionne, il faut quand meme connaitre le SWHID 'directory' du contenu recherche, et bien evidemment, que le contenu soit archive avant, donc il faut passer l'URL et le swh:1:dir correspondant en ligne de commande, ce qui peut etre lourd à faire.
Du coup, l'outil pourrait etre un peu plus evolue: si l'URL normale fonctionne et pointe sur un depot git, et qu'on ne passe pas le swhid en parametre, il pourrait declencher un save code now, et recuperer le bon swhid pour la directory en question (e.g. en utilisant GraphQL pour l'archive), et se rappeler de cela dans un fichier de config.
A creuser, donc: s'il y a des volontaires pour implementer, je veux bien donner des idees, meme si je n'ai pas la bande passante pour implementer cela moi meme